Scheduled Events und Queue Prozesse
Zugegeben, dieser Fall taucht nicht wahnsinnig oft auf. Wenn er es jedoch tut, kann er problematische Konsequenzen haben. Passiert es in einer Produktionsumgebung kann es dazu führen, dass die Produktionsumgebung steht.
Der Usecase
Prozesse in einer Queue ablaufen zu lassen (ich verwende den Begriff Queue im Folgenden für alle Arten von Queues in Mendix. Process Queue, Task Queue,…) ist etwas sehr nützliches. Einerseits kann man lang laufende Prozesse in den Hintergrund auslagern und somit dem Benutzer ein flüssigeres Erlebnis bescheren, andererseits kann man auf diese Weise ein Batch Processing erzeugen um große Aktionen (Datenmigrationen, regelmäßige Synchronisationen,…) in kleine Arbeitspakete aufzuteilen. Somit kann man sicherstellen, dass die Transaktion nicht zu groß wird (was zu Problemen bis hin zum Systemabsturz führen kann).
Was hat das mit Scheduled Events zu tun?
Ein konkreter Usecase der mir bereits mehrfach begegnet ist ist ein regelmäßig im Hintergrund laufender Datenabgleich. Unsere Anwendung muss in einem bestimmten Intervall Daten von einer API abrufen und diese dann lokal verarbeiten. Diese Verarbeitung soll aus den oben genannten Gründen in Arbeitspaketen erfolgen. Wenn man sich bereits mit der Queue befasst hat liegt die Lösung nahe. Ein Scheduled Event ruft in fest definierten Intervallen Daten von der API ab, erzeugt Arbeitspakete und lässt diese nun in der Queue abarbeiten.
Hierbei handelt es sich wahrscheinlich um die Ultimative Lösung und es gibt nichts was man „anders“ machen sollte. Ein typischer Microflow für das Scheduled Event sieht so aus:
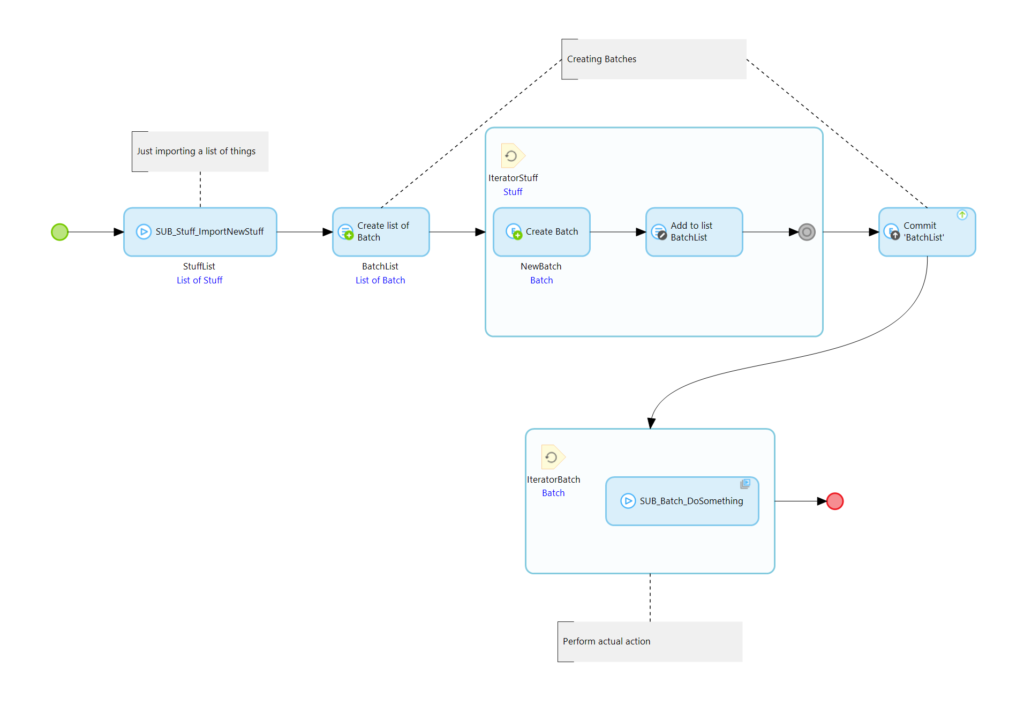
Zunächst importieren wir Daten, dann erzeugen wir Arbeitspakete und führen die Verarbeitung dieser letztlich in der Queue aus.
Aber warum schreibst du denn einen Blog Artikel darüber?
Nun, das was ein Scheduled Event ausmacht ist auch das, was bei einem Scheduled Event zu Problemen führen kann: Es wiederholt sich periodisch.
Dies ist im Normalfall genau das Verhalten was wir bei einem Scheduled Event erzeugen wollen. Es soll alle X Sekunden/Minuten/Stunden/Tage/… ablaufen. Was aber wenn die Ausführung des Scheduled Events länger dauert als die Periode in der es ausgeführt wird?
Der Standardfall
Mendix hat über das oben genannte Problem natürlich bereits nachgedacht und einen Mechanismus etabliert um dem entgegenzusteuern. Wenn man ein Scheduled Event erzeugt kann man definieren wie es sich in diesem Fall verhalten soll.
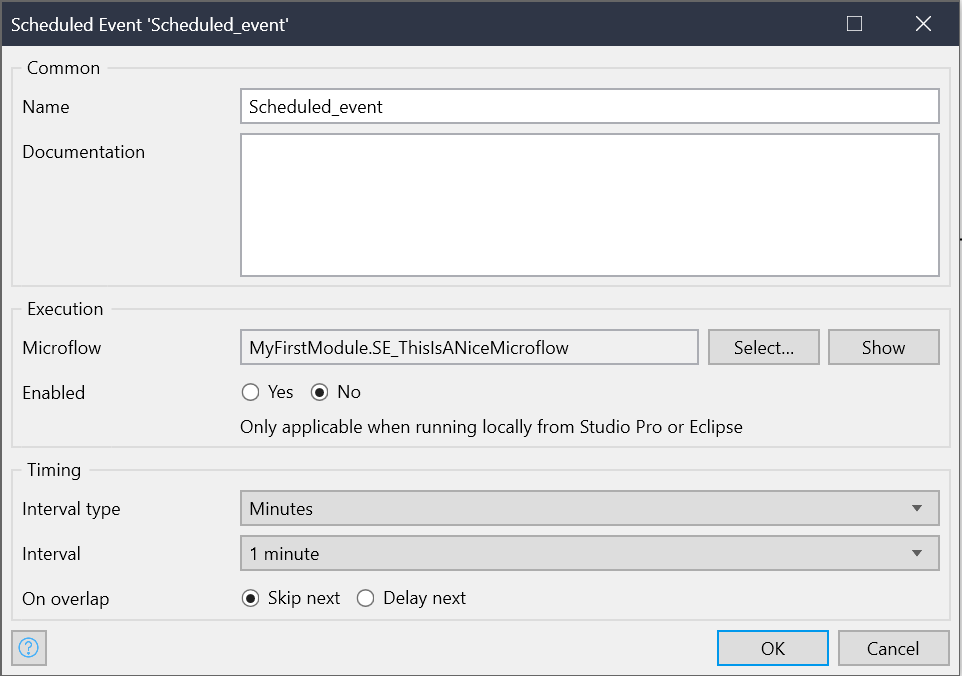
Die „On overlap“ Einstellung lässt uns definieren wie sich das Event verhalten soll wenn die Ausführungszeit die Periode übersteigt. Man kann wählen ob die nächste Ausführung des Events übersprungen oder verzögert werden soll. Wählt man „Skip next“ so wird so lange kein Event ausgeführt bis die Ausführung des laufenden Events beendet ist. Danach geht es mit der normalen Periode weiter. Wählt man Delay, so werden die nachfolgenden Ausführungen verzögert. Sie werden also in eine Art Queue gestellt und abgearbeitet sobald die erste Ausführung beendet ist (Dies birgt auch gewisse Gefahren aber darum soll es hier nicht gehen).
Was ist jetzt mit der Queue?
Werden innerhalb des Scheduled Events Arbeitspakete erzeugt die in einer Queue abgearbeitet werden, so ist es dem Event nicht mehr möglich zu wissen ob bereits alles abgearbeitet ist oder nicht. Es kann lediglich entscheiden ob das erstellen der Arbeitspakete abgeschlossen ist. Dauert nun die eigentliche Verarbeitung der Pakete länger als die Periode zwischen zwei Ausführungen des Events, so werden mit jeder Ausführung mehr und mehr Arbeitspakete in die Queue gestellt. Der Berg an Arbeit wächst kontinuierlich an und wird niemals abgearbeitet.
Dieses Problem lässt sich mit der Standardkonfiguration des Scheduled Events nicht lösen. Ja, man kann vorsorglich eine größere Periode wählen. Aber Dinge sind erstens nicht immer so vorhersehbar und die Nutzer möchten einen Datenabgleich wahrscheinlich möglichst Zeitnah.
Was tun?
Um die genannten Probleme zu verhindern müssen wir das was das Scheduled Event normalerweise automatisch macht in dem Microflow manuell nachbauen. Wir müssen rausfinden ob die vorherige Ausführung bereits abgeschlossen ist oder nicht. Hierzu geben wir unserem Batch Objekt ein Attribut welches als Indikator dafür dient ob die verarbeitung bereits durchlaufen wurde.
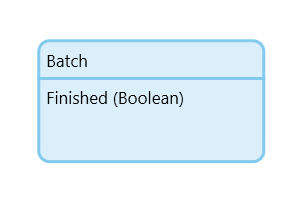
In seiner einfachsten Form ist dies einfach ein Boolean Attribut. Beim Erzeugen des Batches ist das Attribut auf false gesetzt, nach Ablauf der Verarbeitung setzen wir es auf true. Unserem oben vorgestellten Microflow stellen wir eine Datenbankabfrage vor die prüft ob es noch Batches gibt die nicht ausgeführt sind. Das ganze sieht dann so aus:
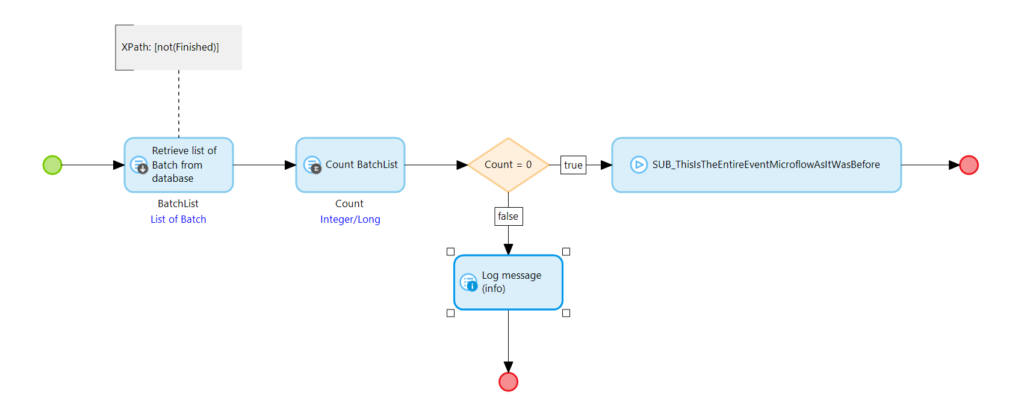
Wir zählen zunächst ob es noch Batches gibt die nicht verarbeitet sind. Sollte es keine mehr geben führen wir den Microflow aus den wir im ersten Beispiel verwendet haben. In der eigentlichen Ausführung in der Queue müssen wir natürlich das Finished Attribut setzen.
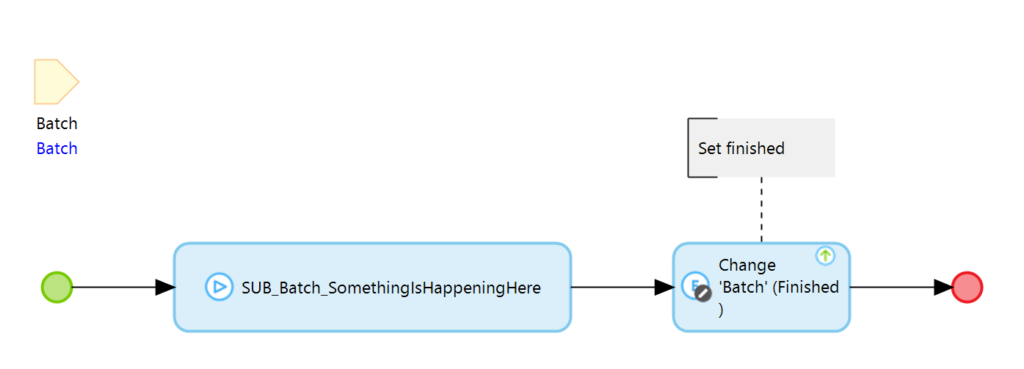
Nun haben wir das „Skip next“ Verhalten für die Verwendung mit der Queue auf sehr einfache Weise nachgebaut und laufen nicht mehr Gefahr, dass zu häufig ausgeführte Events die Queue überlaufen lassen.
Aber was ist mit „Delay next“?
Auch wenn ich von Delay next in den meisten Fällen abraten würde möchte ich der Vollständigkeit halber auch eine Delay Next Variante vorstellen. Hierfür müssen wir eine Schleife in unseren Scheduled Event Microflow einbauen in der wir immer wieder prüfen ob die vorherige abarbeitung abgeschlossen ist. Ich empfehle dringend mit einem Delay zu arbeiten weil ansonsten die Datenbankabfragen so lange unmittelbar nacheinander ausgeführt werden bis das gewünschte Ergebnis erscheint. Dies kann eine enorme Last auf das System ausüben. In den Community Commons gibt es eine Java Action namens Delay die genau das für uns tut. Sie lässt das System warten.
Mit diesem Delay und der Schleife bewaffnet sieht unser Event Microflow nun so aus:
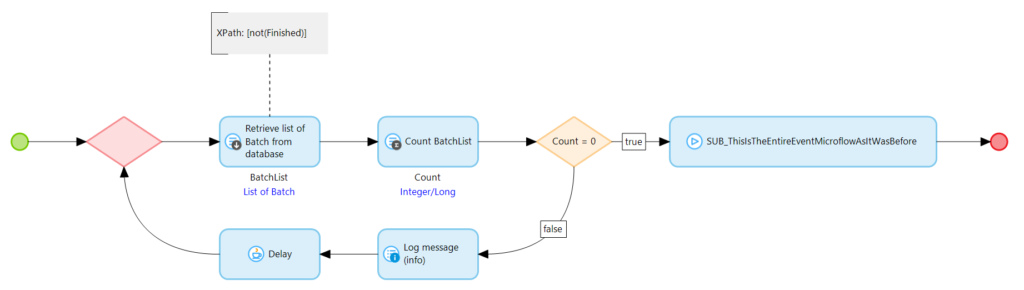
Anstatt die Ausführung abzubrechen wird so lange immer wieder auf die Datenbank geschaut bis es keinen Batch mehr gibt der noch nicht verarbeitet wurde. Sobald dies der Fall ist wird nun die eigentliche Logik des Events ausgeführt. Somit konnten beide Verhalten des Events mit einfachen mitteln auf die Queue erweitert werden und wir können verhindern, dass die Queue durch zu schnelle Event Ausführungen überlastet wird.
Natürlich braucht man das nicht bei jedem Event. Es ist ein kleiner Spezialfall. Aber immer wenn man ein Event sehr oft ausführt und möglicherweise viele Daten verarbeitet sollte man darüber nachdenken solch einen Mechanismus einzubauen. Er lässt sich schnell umsetzen und bewahrt einen möglicherweise vor ernsten Problemen.
Ich hoffe dies war für den ein oder anderen interessant. Ich freue mich wie immer über Feedback und Kommentare.