Eindeutige Fremdschlüssel und Parallelität
Auch wenn Mendix über das Domain Model Relationen selbst verwaltet und man in der Regel wenig mit Schlüsseln und Fremdschlüsseln in Berührung kommt, so ist es sehr wahrscheinlich im Laufe der Zeit doch an einen Punkt zu gelangen an dem man sie benötigt. Typische Beispiele sind hierbei das Vermeiden von Cross-Module-Associations oder Daten die man aus einem Drittsystem erhält und lokal Cachen möchte.
In vielen Fällen ist es hierbei notwendig, dass ein Schlüssel nur einmal existieren darf. Synchronisiert man beispielsweise Datensätze aus einem Fremden System, so will man es vermeiden, den selben Datensatz mehrfach zu speichern. Ein einfacher aber effektiver Ansatz ist die Verwendung des CreateOrRetrieveIfExisting Patterns.
Betrachten wir hierfür folgenden Datensatz.

Das Identifier Attribut ist hierbei der eindeutige Schlüssel. Wird ein Datensatz mit einem bestimmten Schlüssel benötigt, so kann ein CreateOrRetrieveIfExisting Microflow verwendet werden um einen bestehenden Datensatz zu verwenden oder, falls es einen solchen nicht gibt, einen neuen Datensatz anzulegen. Dies findet z.B. in Event getriebenen Systemen Anwendung, bei denen in einem anderen System ein Ereignis einen Datensatz welcher synchron gehalten werden muss anlegt oder verändert. Der entsprechende Microflow würde nun wie folgt aussehen.
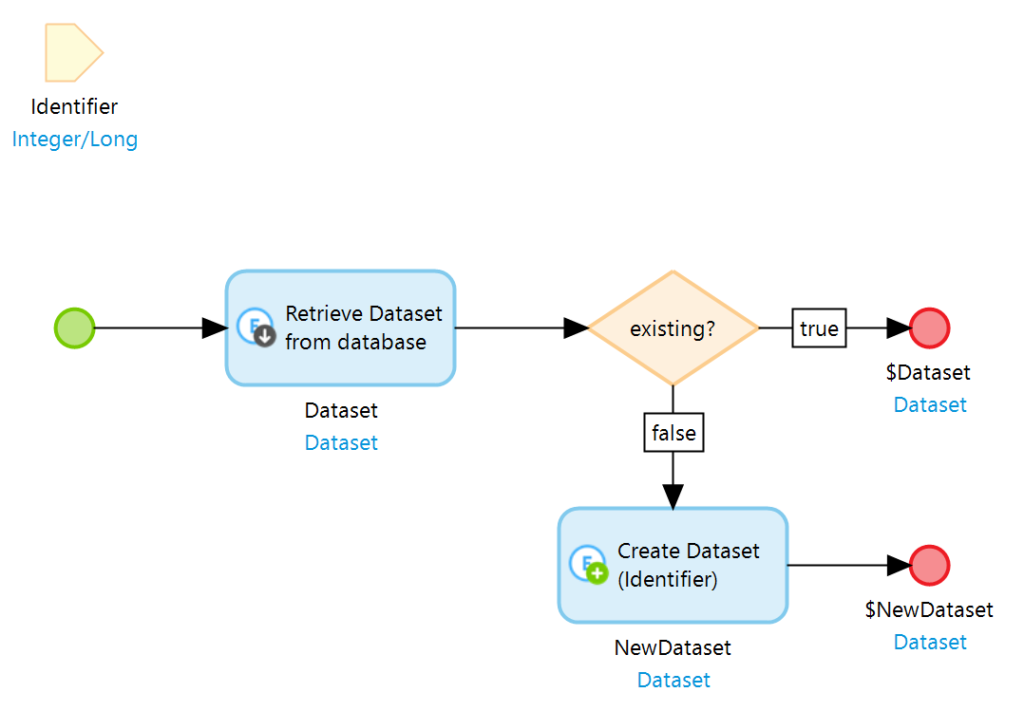
Zu einem gegebenen Identifier sucht das System nun einen Datensatz aus der Datenbank und legt diesen gegebenenfalls an. Man kann somit sicherstellen dass man immer einen Datensatz bekommt und, dass es einen Datensatz jeweils nur ein einziges mal gibt.
Das Problem: Parallelität
Dieses Pattern funktioniert tadellos, hat aber ein Problem. Es kann nicht mit Parallelität umgehen. Insbesondere (aber nicht nur) bei Event getriebener Architektur, kann es passieren, dass es mehrere Ereignisse innerhalb kurzer Zeit gibt, die sich alle auf den selben Datensatz beziehen. Existiert dieser bereits ist das kein Problem. Existiert er zu diesem Zeitpunkt allerdings noch nicht laufen mehrere Prozesse die nichts voneinander wissen. Keiner dieser Prozesse findet das Objekt in der Datenbank denn die Transaktion der anderen Prozesse ist zu diesem Zeitpunkt noch nicht beendet. Dies ist insbesondere dann eine Gefahr wenn es sich um einen Prozess handelt der eine längere Laufzeit hat. Das Resultat ist, dass jeder dieser Prozesse den Datensatz neu anlegt, mit dem Ergebnis, dass es den Datensatz mehrfach in der Datenbank gibt.
Die Lösung: Validierung auf Datenbankebene und Retry Mechanismus
Zunächst müssen wir in der Datenbank ein unique constraint anlegen. Dies lässt sich zum Glück recht einfach über das Mendix Domain Model erledigen. Hierzu wird eine Validation Rule für den Identifier erstellt die wie folgt aussieht.
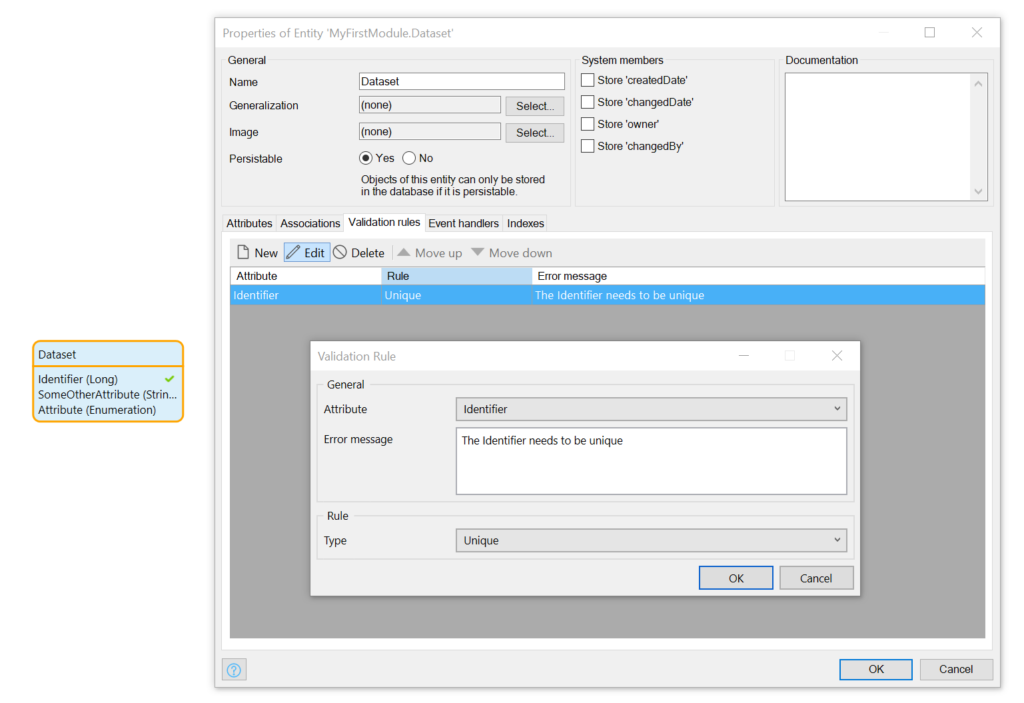
Die Datenbank erlaubt nun schlichtweg nicht mehr, dass es den gleichen Wert mehrfach gibt. Versucht man ein Objekt zu commiten welches einen bereits verwendeten Identifier besitzt, wird eine Exception geworfen.
Wir möchten nun natürlich nicht, dass unser Prozess am Ende mit einer Exception abbricht. Idealerweise möchten wir das Problem schon kennen wenn wir es generieren. Hierzu kann der CreateOrRetrieveIfExisting Microflow wie folgt angepasst werden.
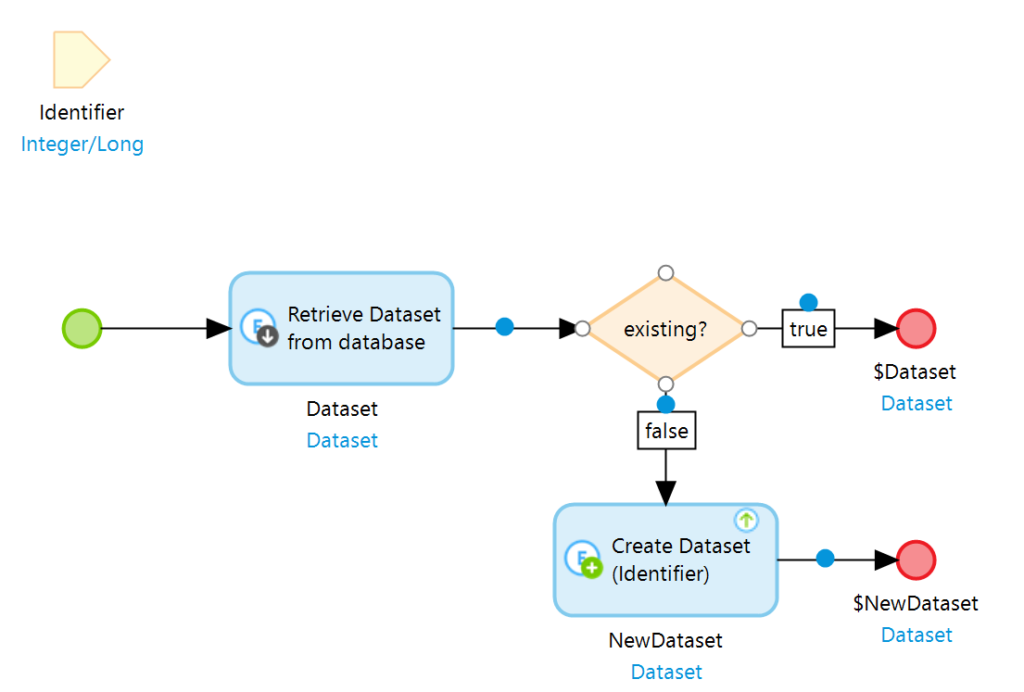
Das Objekt wird nun direkt beim erzeugen gespeichert. Dies führt dazu, dass ein Datenbank lock existiert und andere Prozesse gegebenenfalls auf das Ende des ersten Prozesses warten müssen. Stellt sich nun heraus, dass der erste Prozess das Objekt bereits angelegt hat, so wirft die Create Action eine Exception.
Nun wissen wir dass es ein Problem gibt in dem Moment in dem wir das Problem erzeugen. Es wäre allerdings angenehmer, wenn unser Prozess erfolgreich weiterlaufen würde und nicht wegen einer Exception abbrechen würde. Erweitern wir den Microflow um ein Error Handling in Kombination mit einem retry Mechanismus, so können wir genau diesen Komfort erreichen.
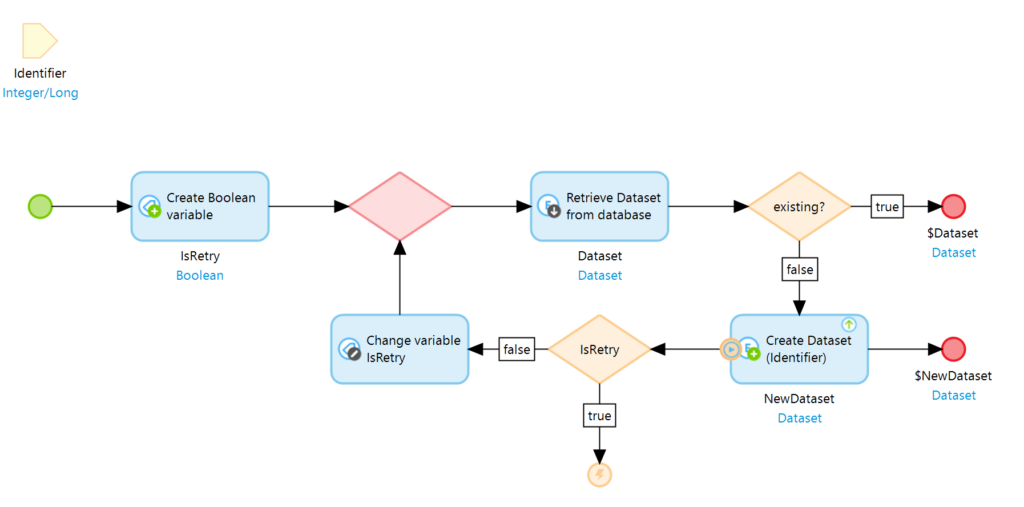
Bei der IsRetry variable handelt es sich um ein boolean welches mit ‚false‘ initialisiert und im Falle eines Fehlers auf ‚true‘ geändert wird. Somit wird sichergestellt, dass der Retry nur ein einziges mal versucht wird. Mehr ist bei diesem Problem auch nicht nötig.
Beendet der erste Prozess nun seine Transaktion, so wird in den anderen Prozessen in der Create Action eine Exception ausgelöst. Diese wird behandelt indem der Microflow ein weiteres mal von vorne beginnt. Durch die abgeschlossene Transaktion des ersten Prozesses wird der Datensatz nun in der Datenbank gefunden und kann verwendet werden. Parallelität existiert immer noch, sofern unterschiedliche Datensätze parallel angelegt werden. Handelt es sich um den gleichen Datensatz so wird beim ersten Anlegeprozess gegebenenfalls darauf gewartet, dass der erste Prozess abgeschlossen ist. Diese Anfragen werden also quasi seriell abgearbeitet, während im weiteren Verlauf wieder Parallelität gegeben ist.
Ich hoffe dieser Artikel ist für den ein oder anderen hilfreich. Ich freue mich wie immer über Feedback.