Mehrere Aggregationen auf einer Liste? Das lässt sich optimieren.
In diesem Beitrag geht es um die Optimierung von Datenbankabfragen. Genauer gesagt um die Optimierung einer speziellen Art der Abfrage, der Aggregation.
Aggregationen in Mendix
Bei einer Aggregation geht es darum bei einer Liste von Datenbankeinträgen die Werte einer bestimmten Spalte miteinander zu verrechnen. Typische Aggregationen sind Summen, bilden des Durchschnittes, suchen des größten oder kleinsten Elementes,…
Wir betrachten hier Aggregationen bei denen uns wirklich nur das Ergebnis interessiert, bei denen wir aber die eigentlichen Werte oder Datenbankeinträge nicht brauchen. Insbesondere geht es auch darum wie man es schaffen kann die Aufrufe zu optimieren wenn man mehrere Aggregationen über die selbe Liste von Objekten braucht.
In Mendix gibt es die „Aggregate List“ Action mit der wir solche Aggregationen auf Listen durchführen können. Betrachten wir das folgende Datenmodel.

Es ist bewusst einfach gewählt um zu zeigen, dass Optimierungen bereits bei sehr einfachen Datenstrukturen Sinnvoll sind. Zum ausprobieren habe ich eine Datenbank (PostgreSQL) mit 578611 Datensätzen gefüllt und die vier Attribute mit zufälligen Werten belegt. Die Aufgabe die ich erledigen möchte ist es für jedes dieer Attribute eine Summe über alle Datensätze zu bilden.
Der offensichtliche Weg
Ein sehr einfacher (und funktionierender) Ansatz dieses Problem zu lösen ist der folgende.

In diesem Microflow wird zunächst ein Retrieve ausgeführt. Auf der daraus resultierenden Liste werden nun nacheinander die Aggregationen gemacht. Die Ergebnisse werden in ein Ergebnisobjekt gespeichert. Dies funktioniert tadellos und das Ergebnis ist das gewünschte. Die Ausführungsgeschwindigkeit ist allerdings sehr schlecht. Auf meiner Beispieldatenbank hat es ca. 2500 Millisekunden gedauert diesen Microflow auszuführen.
Das Problem bei dieser Lösung ist, dass die Liste zunächste von der Datenbank in die Runtime geladen wird. Dort wird nun aggregiert. Wer schon einmal direkt mit Datenbanken gearbeitet hat weiß aber, dass Datenbanken selbst Aggregationen durchführen können. Datenbanken sind darin sehr gut. Wir wünschen uns also einen Weg die Datenbank die Arbeit erledigen zu lassen.
Best Practice
Das Problem bei der oben genannten Lösung besteht darin, dass Mendix eine Aggregation nur dann optimiert, wenn Retrieve und Aggregation erstens unmittelbar zusammenstehen und wenn zweitens keine andere Aktion mit der Liste ausgeführt wird (selbst wenn es „nur“ andere Aggregationen sind). Auch wenn es auf den ersten Blick nach mehr Aufwand aussieht besteht also eine bessere Möglichkeit darin, für jede Aggregation einen eigenen Retrieve zu machen. Der zugehörige Microflow sieht dann wie folgt aus.
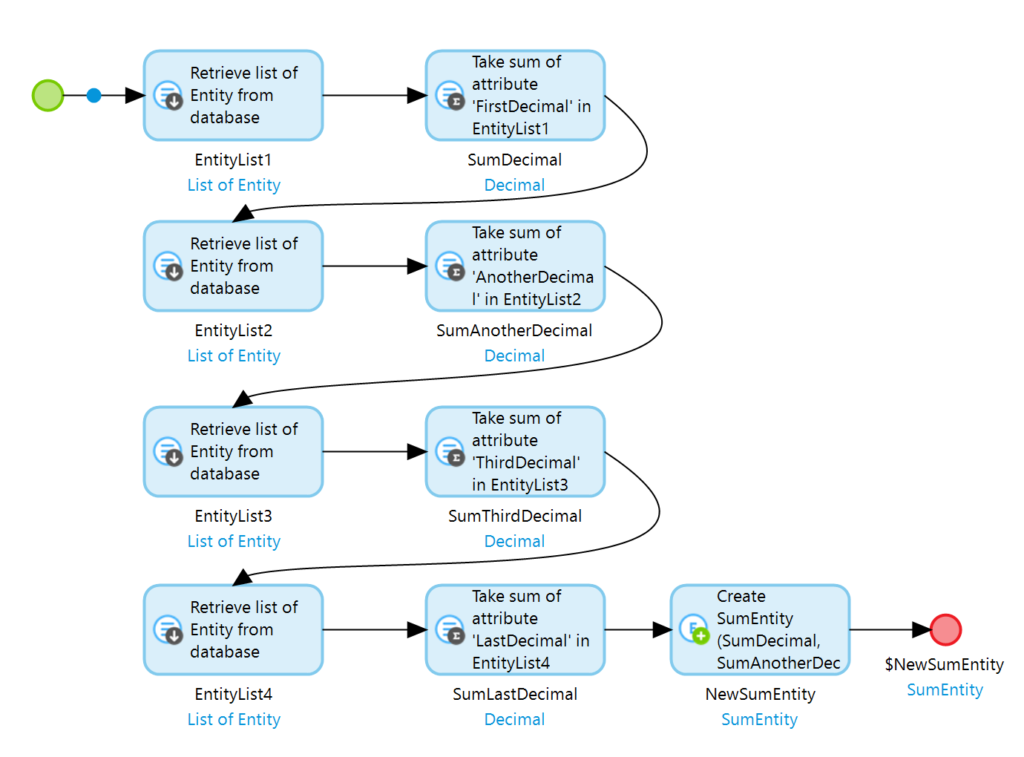
In diesem Microflow wird die selbe Liste immer wieder abgerufen und direkt im Anschluss eine Aggregation durchgeführt. Da keine dieser Listen weiter verwendet wird, optimiert Mendix die Aufrufe und führt die Aggregation direkt auf der Datenbank aus. Die Listen werden nicht in die Runtime geladen. Lediglich die Ergebnisse der Aggregationen finden sich hier wieder.
Auf meiner Beispieldatenbank wird dieser Microflow in ca. 240 Millisekunden ausgeführt. Er ist also um den Faktor 10 schneller als die offensichtliche Lösung.
Aber warum sollte man 4 Datenbankaufrufe machen um jeweils ein Ergebnis zu bekommen? In einer Datenbank könnte man das ganze doch in einem Aufruf verarbeiten? Stimmt. Die Finale Optimierung des ganzen macht sich genau das zu Nutze.
Noch schneller mit OQL
Zugegeben, diese Lösung ist mit Mendix Boardmitteln nicht mehr zu machen. Wir benötigen dazu das OQL Modul aus dem Mendix Marketplace. Mit Hilfe diese Moduls lassen sich OQL Queries auf der Datenbank ausführen. Dadurch ist es uns nun Möglich alle Aggregationen in einer einzelnen Datenbankinteraktion unterzubringen. Der zugehörige Microflow sieht so aus.
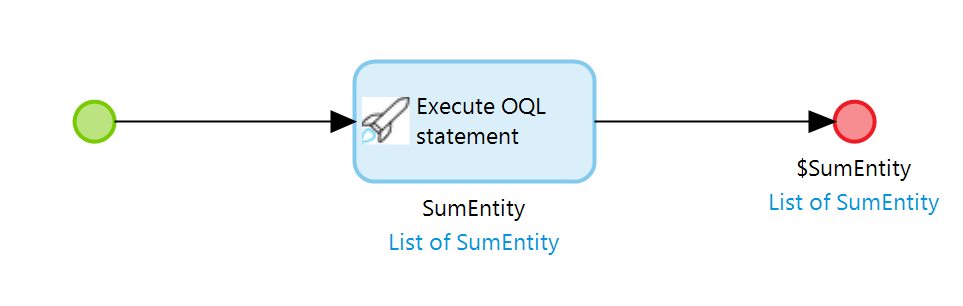
Ja, es ist tatsächlich nur eine einzige Aktion. Folgendes Statement wird hierin ausgeführt.
SELECT
SUM(Entity.FirstDecimal) AS SumDecimal,
SUM(Entity.AnotherDecimal) AS SumAnotherDecimal,
SUM(Entity.ThirdDecimal) AS SumThirdDecimal,
SUM(Entity.LastDecimal) AS SumLastDecimal
FROM
MyFirstModule.Entity AS EntityDie Execute OQL statement Aktion führt den Code auf der Datenbank aus und erzeugt direkt ein Ergebnisobjekt für uns. Hierbei ist lediglich zu beachten, dass die gewählten Aliase mit den Attributsnamen der Ergebnisentity übereinstimmen.
Auf meiner Beispieldatenbank ist dieser Microflow in ca. 90 Millisekunden ausgeführt. Es ist also nochmal ein erheblicher Performancesprung zwischen der Best Practice und der OQL Variante.
Fazit
Bei Aggregationen sollte man zumindest immer auf die Mendix Best Practice zurückgreifen und Listen ausschließlich für eine Aggregation abrufen. Nur dann optimiert Mendix die Ausführung und lässt die Datenbank die Arbeit verrichten. In Manchen fällen, insbesondere bei vielen Datensätzen oder komplexen Datenstrukturen, kann es nützlich sein durch den Einsatz von OQL noch weiter zu optimieren. Diese Grafik zeigt den Unterschied in der Ausführungsgeschwindigkeit eindrucksvoll.
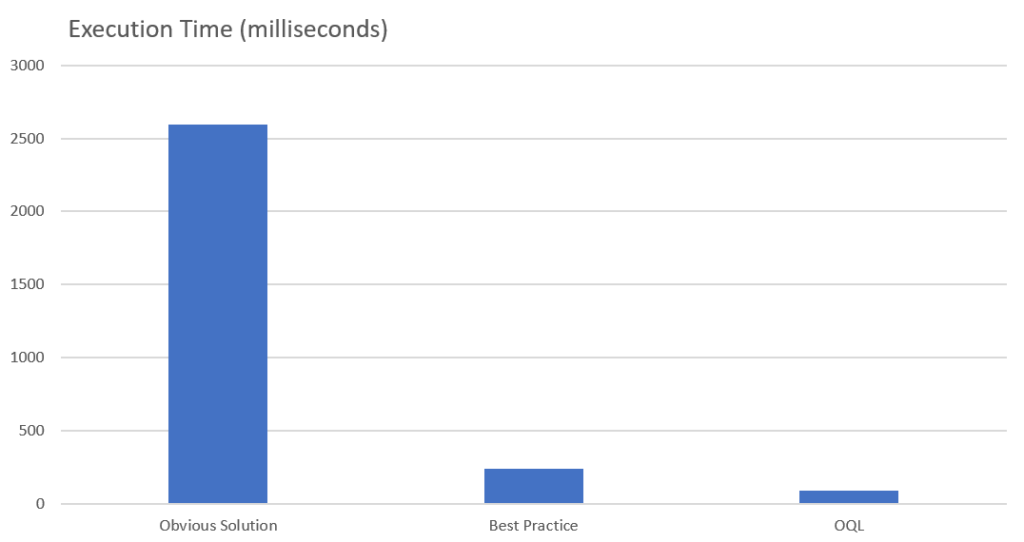
Hier wird deutlich wie schlecht die Performance bei der offensichtlichen Lösung sein kann. Der Unterschied zwischen der Best Practice und der OQL Lösung wird nochmal deutlich, wenn man nur diese beiden gegenüberstellt.
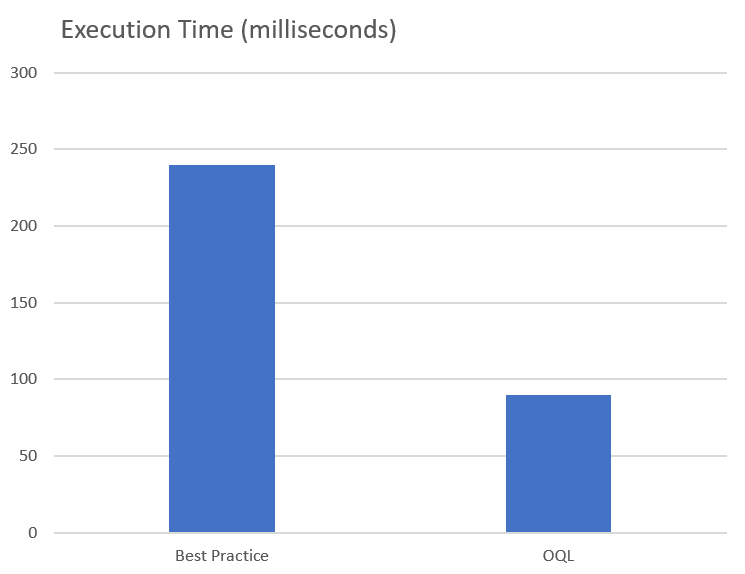
Man sollte hierbei auch bedenken, dass es sich in dem gezeigten Beispiel um sehr einfache Abfragen handelt. Die Datenbank muss keinerlei komplizierte Joins ausführen. Sind diese notwendig (und in realen Beispielen sind sie das fast immer) kann der Unterschied noch wesentlich gravierender ausfallen.
Ich wünsche euch wie immer viel Spaß beim ausprobieren. Ich freue mich immer sehr über euer Feedback.